
Ditching ingress-nginx.
Why we picked Cilium Gateway API over every other option.


What actually happened to ingress-nginx
This is worth understanding because it changes how you think about urgency. ingress-nginx didn’t get deprecated because of a technical failure. It didn’t get replaced by something better from the same team. It got archived because two people had been maintaining it alone for years, on their personal time, and they couldn’t keep doing it.
By the time the archive happened, the codebase was in a state where adding security fixes was genuinely difficult. The annotation system — the way you configured everything from timeouts to CORS to auth — had become a security liability. The Kubernetes Security Response Committee flagged several annotation-based features as unsafe. There was an attempt to build a replacement called InGate that never got enough contributors. The maintainers eventually announced what everyone who looked closely already suspected: the project was unsustainable.
Your existing ingress-nginx deployment keeps working. Nothing breaks immediately. But every unpatched vulnerability from now on is yours to own. If you need extra time to do this migration properly, take it — a rushed migration is worse than running a slightly outdated ingress controller while you plan carefully.
The options we actually considered
When something you depend on gets archived, the tempting move is to just pick whatever someone else picked and move on. We didn’t do that. We spent real time on each option, and I want to explain why we rejected the ones we did.

Decision matrix — four options evaluated, one chosen. Colors: green = pros, red = blockers, orange = caveats.
Why we rejected Cilium Ingress Controller corrected v2
The Cilium Ingress Controller is the drop-in option — change ingressClassName: nginx to ingressClassName: cilium and you’re mostly done.
The specific thing that killed it for us was ArgoCD. Cilium Ingress doesn’t support TLS backends — meaning if ArgoCD serves HTTPS internally and your ingress controller needs to connect to it over HTTPS, Cilium Ingress can’t do that. That’s a hard blocker. The maintainer confirmed it’s a known gap and that the effort is going into BackendTLSPolicy in Gateway API instead.
Also: most nginx-specific annotations are simply not applicable in Cilium Ingress. This isn’t exactly “silently ignored” — they’re foreign annotations to a different controller. But the practical effect is the same: your carefully tuned nginx config does nothing, and you only find out when something behaves differently than expected.
Why we rejected kgateway
kgateway is a solid project with good CNCF backing and growing community momentum. The Plum Engineering team chose it and their migration went well. But here’s our specific problem: we already run Cilium, which already runs Envoy internally on every node. Adding kgateway means running a second Envoy on every node just for ingress. That’s wasted resources and an extra component to upgrade independently.
If we didn’t have Cilium, kgateway would be a sensible choice. But the calculus changes when you’re already running the same dataplane.
Why we rejected Traefik
Traefik has a compatibility layer that understands nginx-style Ingress resources without full rewriting — genuinely useful for teams with large ingress surface areas. But same issue as kgateway: it runs its own proxy, independent of Cilium’s embedded Envoy. You’d have two separate network stacks operating in parallel on every node. Some teams run exactly this and it works fine. For MetalKube with four engineers, fewer moving parts is always better.
What Cilium Gateway API actually is
Before getting into the plan, it’s worth understanding what Gateway API actually does differently from Ingress — because it’s not just a rename with better syntax.
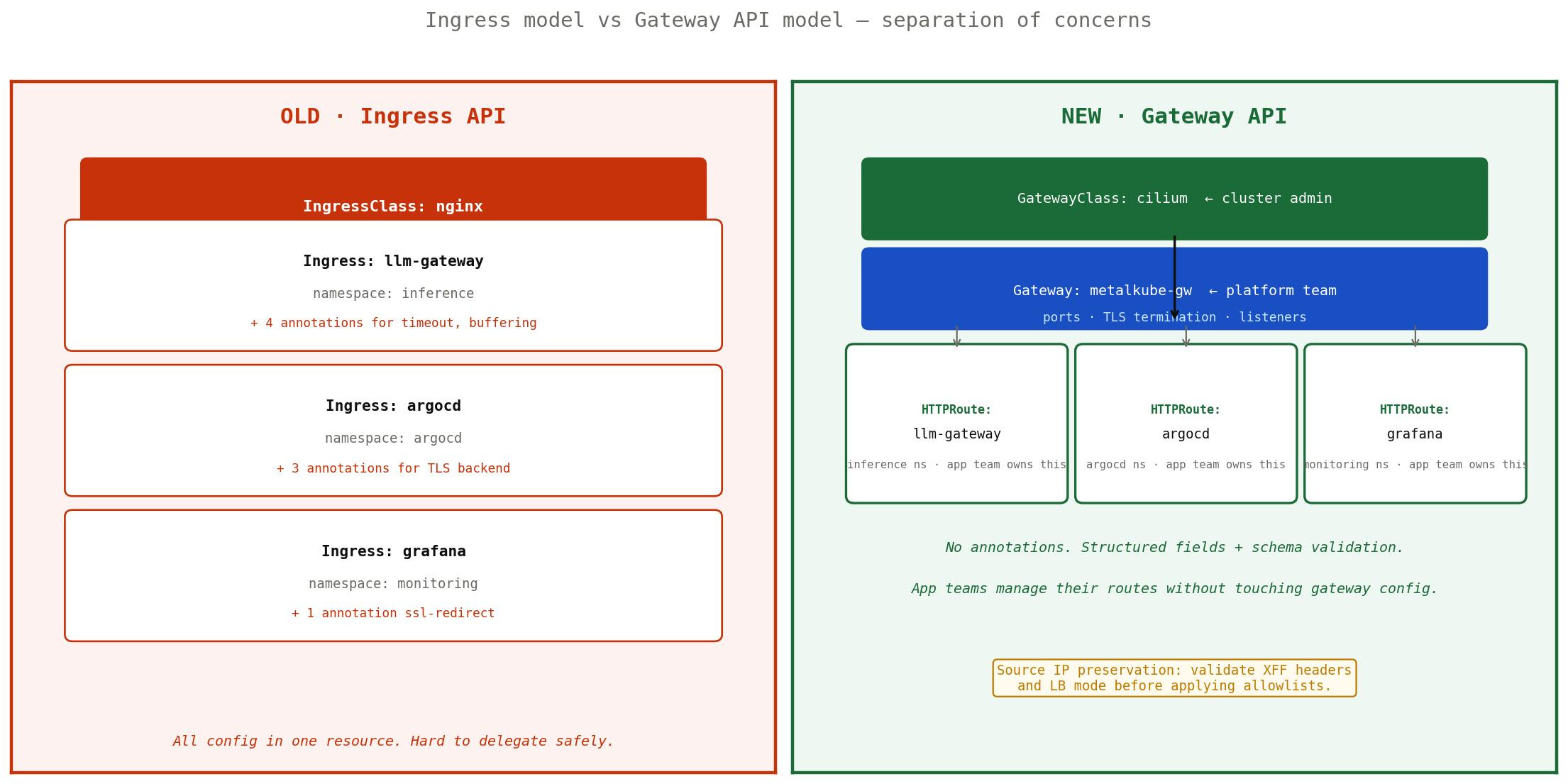
Role separation: platform team owns the Gateway config, app teams own their HTTPRoutes. Note the source IP warning — relevant for Qdrant.
The key shift is role separation. With Ingress, the cluster admin config (ports, TLS) and the application config (routing rules) live in the same resource. Gateway API splits this into three layers: GatewayClass (the controller type), Gateway (ports, TLS, listeners — managed by platform team), and HTTPRoute (routing rules — managed per namespace by app teams).
More importantly: structured fields instead of annotations. Everything you configured with nginx.ingress.kubernetes.io/something: "somevalue" now has a proper YAML field with schema validation. If you typo an annotation, nginx silently ignores it. If you typo an HTTPRoute field, Kubernetes rejects it immediately with a clear error message.
The annotation problem in one sentence
Annotations are arbitrary strings with no schema and no portability guarantee. They were always a workaround for a limited API. Gateway API was specifically designed to make them unnecessary — and that’s why your nginx-specific annotations don’t translate to any other controller.
Current state of MetalKube ingress
Before planning anything, I ran the inventory. Here’s what we actually have and how complex each migration is:
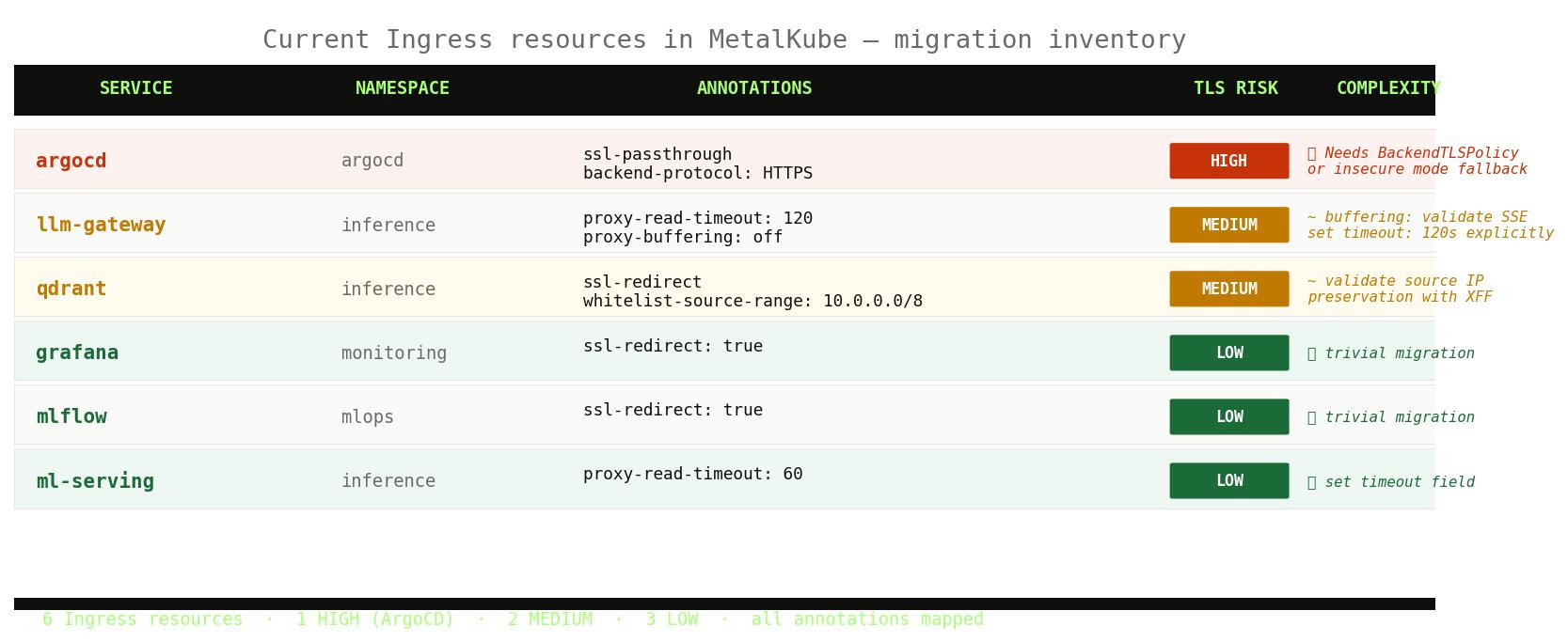
6 Ingress resources · 1 HIGH (ArgoCD) · 2 MEDIUM · 3 LOW · all annotations mapped to Gateway API equivalents
Six Ingress resources total. Manageable. The ArgoCD one needs the most careful handling because of TLS backend. The LLM Gateway has proxy-buffering: off and proxy-read-timeout: 120 — these need attention.
On the buffering annotation: Envoy is a streaming proxy and generally handles SSE connections without extra config. However, I’m not saying “this annotation is unnecessary and you’re done.” You should validate SSE streaming explicitly with your actual routes before assuming it works the same. The behavior can vary depending on filters, HTTP/2 framing, and upstream configuration. What I can say is that the concepts are different enough that you can’t just map one to the other without testing.
The migration plan — four phases
We’re doing this in four phases over about three weeks. The approach is parallel running — ingress-nginx stays alive until every service is validated on the new Gateway. No big bang, no scheduled downtime.
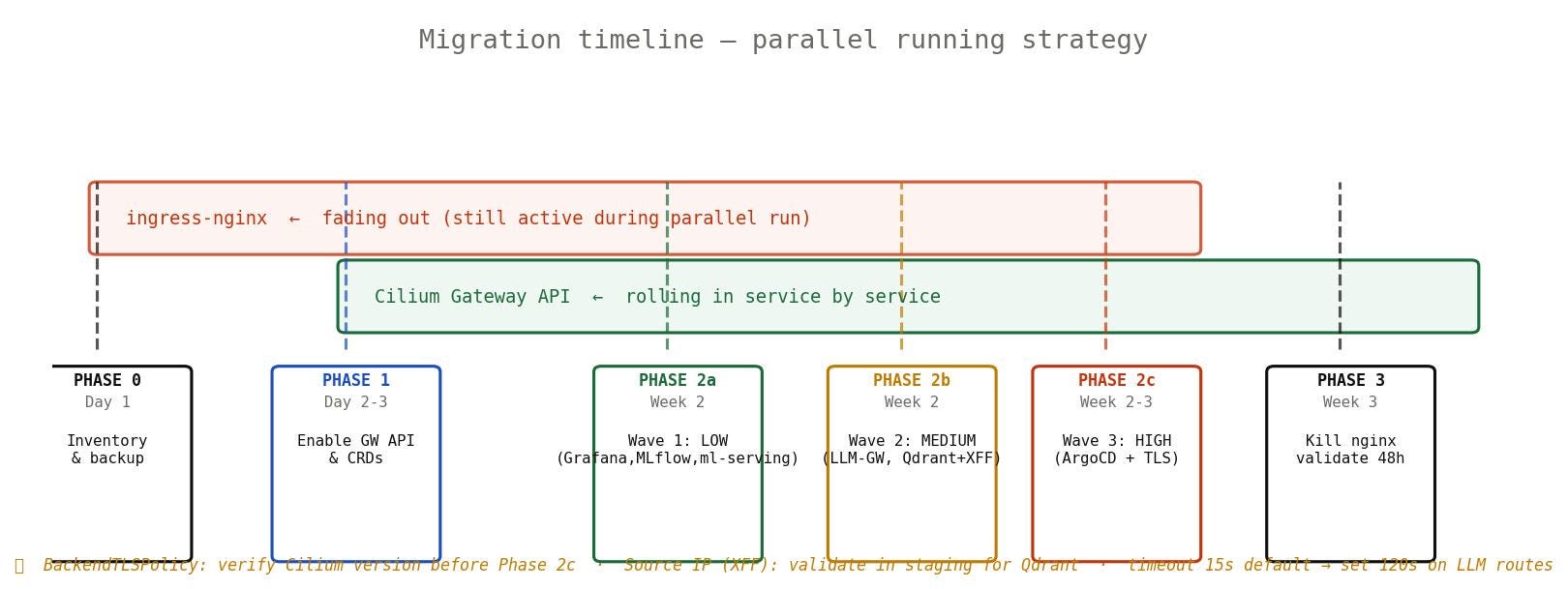
Parallel running: both controllers active simultaneously until every service is validated. Note the three corrected caveats at the bottom.
Phase 0 Inventory — Day 1
Before touching anything, run a full audit. We need to know every annotation, every TLS configuration, and every path pattern that might behave differently under Gateway API’s stricter matching.
# Full inventory of all Ingress resources
kubectl get ingress -A -o json | jq '
[.items[] | {
name: .metadata.name,
namespace: .metadata.namespace,
host: [.spec.rules[].host],
tls: .spec.tls,
annotations: .metadata.annotations
}]'
# Hunt for TLS-related annotations specifically
kubectl get ingress -A -o json | jq '
[.items[] |
select(.metadata.annotations |
to_entries[] | .key | test("ssl|tls|https|backend-protocol|proxy")
) | {
name: .metadata.name,
namespace: .metadata.namespace,
relevant_annotations: [.metadata.annotations |
to_entries[] |
select(.key | test("ssl|tls|https|backend-protocol|proxy"))]
}]'
# Backup everything before touching anything
kubectl get ingress -A -o yaml > ingress-backup-$(date +%Y%m%d).yaml
# Also check cert-manager version — needs >= 1.12 for Gateway API
kubectl get pods -n cert-manager \
-o jsonpath='{.items[0].spec.containers[0].image}'Phase 1 Enable Cilium Gateway API — Day 2-3
Two things to do: install the Gateway API CRDs (pinned version — see warning below), then enable the feature in Cilium via ArgoCD.
CRD version pinning — do not skip corrected v2
In early 2026 there were reports of Gateway API CRDs v1.5 causing crashes in multiple implementations including Cilium. Always pin the CRD version. We’re using v1.2.1 which is confirmed stable. Check the Cilium compatibility matrix for your specific version before going higher.
# Install Gateway API CRDs — pinned version, not latest
kubectl apply -f \
https://github.com/kubernetes-sigs/gateway-api/releases/download/v1.2.1/standard-install.yaml
# Verify CRDs installed correctly
kubectl get crd | grep gateway.networking.k8s.io
# Expect: gateways, gatewayclasses, httproutes, grpcroutes, referencegrantsThen update Cilium’s Helm values via the ArgoCD Application — this is a Git commit, not a manual kubectl:
# gitops/infra/cilium/values.yaml
gatewayAPI:
enabled: true
secretsNamespace:
name: kube-system
create: false
sync: false
# After ArgoCD syncs — verify GatewayClass is Accepted
kubectl get gatewayclass
# NAME CONTROLLER ACCEPTED AGE
# cilium io.cilium/gateway-controller True 2mOnce the GatewayClass is accepted, create the shared Gateway. On bare metal Hetzner, this requires LB-IPAM or L2 announcements to be already configured in Cilium — the Gateway doesn’t magically acquire an IP on its own:
Bare metal IP assignment — not automatic corrected v2
On bare metal, the Gateway needs a way to get an external IP. Options: Cilium LB-IPAM (which we have configured), L2 announcements, BGP, or a separate load balancer. The annotation below works only if LB-IPAM is already set up with an IP pool that includes your Hetzner floating IP. If this isn’t configured, the Gateway will stay in “Pending” forever.
# gitops/infra/gateway/gateway.yaml
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: metalkube-gateway
namespace: kube-system
annotations:
# Works only with Cilium LB-IPAM configured with a pool containing this IP
io.cilium/lb-ipam-ips: "192.168.1.100"
spec:
gatewayClassName: cilium
listeners:
- name: http
port: 80
protocol: HTTP
allowedRoutes:
namespaces:
from: All
- name: https
port: 443
protocol: HTTPS
tls:
mode: Terminate
certificateRefs:
- name: metalkube-wildcard-tls
namespace: kube-system
allowedRoutes:
namespaces:
from: All
# Verify it gets an address (may take 30-60s)
kubectl get gateway -n kube-system metalkube-gateway
# NAME CLASS ADDRESS PROGRAMMED
# metalkube-gateway cilium 192.168.1.100 TruePhase 2 Migrate services — Wave by wave
Wave 1 — Low complexity (Grafana, MLflow, ml-serving)
These only use ssl-redirect and basic path routing. The translation is clean:
# Before: Ingress with nginx annotation
annotations:
nginx.ingress.kubernetes.io/ssl-redirect: "true"
---
# After: HTTPRoute (ssl-redirect is now a Gateway listener concern, not per-route)
# The HTTPS listener on the Gateway handles TLS termination centrally
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: grafana
namespace: monitoring
spec:
parentRefs:
- name: metalkube-gateway
namespace: kube-system
hostnames:
- "grafana.metalkube.internal"
rules:
- matches:
- path:
type: PathPrefix
value: /
backendRefs:
- name: grafana
port: 3000Wave 2 — Medium complexity (LLM Gateway, Qdrant)
The LLM Gateway needs explicit timeout configuration. And the proxy-buffering: off annotation — as mentioned earlier, validate this with real SSE tests before assuming it’s unnecessary:
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: llm-gateway
namespace: inference
spec:
parentRefs:
- name: metalkube-gateway
namespace: kube-system
hostnames:
- "api.metalkube.internal"
rules:
- matches:
- path:
type: PathPrefix
value: /
timeouts:
request: "120s" # replaces proxy-read-timeout: 120
backendRequest: "120s"
# proxy-buffering: off → validate SSE behavior explicitly in staging
# Envoy is streaming-friendly but don't assume without testing
backendRefs:
- name: llm-gateway
port: 8080For Qdrant, the whitelist-source-range annotation previously restricted access by client IP. The natural move is a CiliumNetworkPolicy — but there’s an important caveat about source IP:
Source IP preservation — validate before assuming corrected v2
When traffic goes through a Gateway proxy, the source IP the backend sees may be the Gateway’s IP, not the original client IP. This depends on the load balancer mode, whether XFF (X-Forwarded-For) headers are set, and whether your backend reads them. For Qdrant’s allowlist, verify the actual source IP your backend sees before writing the network policy. A policy based on the wrong IP assumption will either block legitimate traffic or allow everything. Test in staging first with kubectl exec to see what IP Qdrant actually receives.
# Verify source IP BEFORE writing the policy
# Run from inside Qdrant pod — what IP do incoming connections show?
kubectl exec -n inference qdrant-0 -- \
sh -c "ss -tnp | grep 6333"
# If source IP is the Gateway's cluster IP, you need XFF-based policy instead
# If source IP is the original client IP, CiliumNetworkPolicy works directly
# CiliumNetworkPolicy — only after source IP validation
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
name: qdrant-access
namespace: inference
spec:
endpointSelector:
matchLabels:
app: qdrant
ingress:
- fromEntities:
- cluster
- fromCIDR:
- "10.0.0.0/8"Wave 3 — High complexity (ArgoCD) corrected v2
ArgoCD is the most complex because it uses TLS on the backend. Gateway API handles this with BackendTLSPolicy. Before attempting this wave, check your exact Cilium version against the compatibility matrix. The maintainer confirmed active implementation — but “active” in late 2024 doesn’t mean “done in your exact deployed version.”
# Step 1: Check your exact Cilium version
kubectl get pods -n kube-system -l k8s-app=cilium \
-o jsonpath='{.items[0].spec.containers[0].image}'
# Step 2: Check if BackendTLSPolicy CRD exists
kubectl get crd backendtlspolicies.gateway.networking.k8s.io
# If "not found" → use the ArgoCD insecure mode fallback below
# Option A: BackendTLSPolicy (if supported in your version)
apiVersion: gateway.networking.k8s.io/v1alpha3
kind: BackendTLSPolicy
metadata:
name: argocd-backend-tls
namespace: argocd
spec:
targetRefs:
- group: ""
kind: Service
name: argocd-server
validation:
wellKnownCACertificates: System
hostname: "argocd.metalkube.internal"
---
# Option B: ArgoCD insecure mode (fallback if BackendTLSPolicy not ready)
# ArgoCD serves HTTP internally, TLS terminates at the Gateway
# This is ArgoCD's option 1 in their own docs — not a workaround, it's supported
# In argocd-cmd-params-cm ConfigMap:
data:
server.insecure: "true"Why insecure mode isn’t actually insecure here
ArgoCD “insecure mode” means HTTP between the Gateway and the ArgoCD pod. TLS is still end-to-end between the user and the Gateway. The Gateway-to-ArgoCD hop is inside the cluster, on Cilium’s network. If you have Cilium’s WireGuard or IPSec encryption enabled for intra-cluster traffic, that hop is also encrypted at the network layer. This is ArgoCD’s recommended option 1, not a hack.
Phase 3 Remove ingress-nginx — Week 3
Only after 48 hours of stable operation with all HTTPRoutes validated do we remove ingress-nginx:
# All HTTPRoutes must be Accepted and Programmed before proceeding
kubectl get httproute -A
# Every row should show: True / True under ACCEPTED / PROGRAMMED
# Check Hubble for any drops or errors on the new routes
hubble observe --namespace inference --since 48h | grep -E "DROPPED|ERROR"
# Remove ingress-nginx
helm uninstall ingress-nginx -n ingress-nginx
kubectl delete namespace ingress-nginx
# Verify no Ingress objects remain
kubectl get ingress -A
# Should return: No resources foundHonest pros and cons
The version of this section in the first draft was too optimistic. Here’s the corrected version with real tradeoffs:

Corrected v2 tradeoffs — less marketing, more reality. Orange = known caveats, red = real costs.
What can go wrong — the corrected list
Path matching is stricter than nginx
nginx was lenient about trailing slashes, overlapping paths, and partial matches. Gateway API is strict. PathPrefix: /api matches /api and /api/anything. Exact: /api only matches /api. The Plum team found an endpoint that had been accidentally matching paths it shouldn’t have been matching for an unknown amount of time — and nobody noticed. Audit your paths before migrating.
Default timeout is 15s, not 60s
Envoy’s default request timeout is 15 seconds. nginx’s was 60 seconds. For LLM inference routes that can take 30-90 seconds for long Ollama completions, this is a silent failure mode — requests that worked before will start timing out with no obvious change in your code. Set explicit timeouts on every inference route.
Source IP and XFF headers
This was missing from the first draft. When traffic passes through a proxy, the source IP the backend sees may change. For any service that uses client IP for allowlisting, rate limiting, or audit logging, validate what IP your backend actually receives before writing policies based on IP assumptions. Test this in staging before Wave 2.
BackendTLSPolicy — check your version first
The first draft implied this was “coming soon” as if it were available. Reality: availability depends on your exact Cilium version. Check the CRD exists before planning ArgoCD migration on it. Have the insecure mode fallback ready regardless.
LB-IPAM must be pre-configured on bare metal
Also missing from v1. The Gateway doesn’t self-assign an IP on bare metal. Cilium LB-IPAM, L2 announcements, or BGP must already be configured and working with an IP pool that includes your target address. Verify this before Phase 1.
What success looks like
✓All 6 Ingress resources deleted. kubectl get ingress -A returns nothing.
✓ingress-nginx namespace deleted. Zero NGINX processes running on any node.
✓All HTTPRoutes: Accepted: True and Programmed: True.
✓Hubble shows clean traffic for all 6 services over 48 hours post-migration.
✓LLM Gateway SSE streaming validated. Ollama responses complete without timeout at p99.
✓ArgoCD accessible and syncing. TLS working regardless of which option (A or B) we used.
✓Source IP validated for Qdrant. Allowlist behavior confirmed matches previous behavior.
✓Grafana, MLflow, ml-serving all load correctly on first try.